
۱٫ مقدمه
ما فرض میکنیم که رویکرد زنجیرهای از فکر (CoT) در مهندسی سریع، روشی دقیقتر و روشنتر برای حمایت از ایدههای دانشآموزان در یک محیط ایجاد دانش فراهم میکند، بنابراین ظرفیت دانشآموزان را برای تولید و بهبود ایدهها و در عین حال افزایش کلی میدهد. کیفیت گفتمان دانشسازی که با استفاده از LLM تسهیل میشود. اهمیت این توسعه در این است که چگونه یک رویکرد فقط اعلان میتواند امکانات بیشتری را برای کار بدون مجموعه دادههای آموزشی بزرگ و توانایی یک مدل نقطه بازرسی واحد برای انجام بسیاری از وظایف بدون از دست دادن کلیت را آشکار کند. با استفاده از زنجیره فکری برای ایجاد دانش و استدلال عقل سلیم، این کار قصد دارد به حوزه هوش مصنوعی کاربردی برای اهداف آموزشی کمک کند.
۲٫ پیشینه و ادبیات
۲٫۱٫ ظهور AI و LLM های مولد
۲٫۲٫ نقش و رویکردهای مختلف مهندسی سریع
مهندسی سریع، همانطور که با یادگیری درون متنی و تحریک امکان پذیر شد، پس از معرفی ChatGPT اهمیت پیدا کرد، زیرا روش اصلی ورودی و تعامل با LLM صدور متن به آن برای دریافت پاسخ یا از نظر فنی دستورالعملی برای LLM است. . هنگام برقراری ارتباط با یک LLM مانند ChatGPT، از دستورات – از جمله سؤالات، ادعاها و اظهارات – استفاده می شود و کاربران انتظار پاسخ دقیق و کافی را دارند.
اعلان نیز اشکال مختلفی دارد و در میان رویکردهای مختلف، اعلان استاندارد به عنوان رویکرد اساسی در نظر گرفته می شود و اغلب برای محک زدن عملکردهای LLM استفاده می شود. چندین رویکرد وجود دارد، از جمله موارد زیر:
-
ضربه صفر. این امر مستلزم ارائه یک توصیف زبان طبیعی از کار به مدل بدون مثال و درخواست برای نتیجه است.
-
تک شات. یک نمونه واحد به مدل ارائه می شود تا بتواند نتیجه ای مشابه آنچه در نظر گرفته شده است ارائه دهد و اغلب بهتر از مدل بدون نمونه است.
-
چند شات. مجموعهای از نمایشها یا نمونههای با کیفیت بالا در زمان استنتاج به مدل معرفی میشوند که از هر دو جفت ورودی-خروجی برای یک کار هدف تشکیل شده است، اساساً برای اینکه مدل نتیجهای را ارائه دهد که هدف و معیارهای انسان را با عملکرد بهتر در نظر بگیرد. که اغلب بهتر از تلاش های صفر و یک شلیک است.
۲٫۳٫ زنجیره فکر (CoT)
فرآیندهای استدلالی پیچیده که اغلب شامل ایدهها و طرحهای پیچیده میشوند، احتمالاً به مراحل میانی نیاز دارند که منجر به اجماع و راهحلهای نهایی میشوند، که تحریک چند شات میتواند تا حدودی نشان دهد.
-
اولاً، باید به مدلها اجازه داده شود که مسائل چند مرحلهای را به مراحل میانی تقسیم کنند، که در صورت نیاز میتوان با منابع بیشتری پیادهسازی کرد.
-
در مرحله بعد، CoT به عنوان پنجره ای قابل تفسیر به رفتار مدل می تواند به مدل اجازه دهد تصمیم بگیرد که چگونه بهترین پاسخ را پشتیبانی کند.
-
استدلال CoT برای حسابی، استدلال عقل سلیم، و دستکاری نمادین، با کاربرد بالقوه برای کارهایی که انسان می تواند از طریق زبان حل کند، استفاده می شود.
-
استدلال CoT را می توان به آسانی از طریق نمونه هایی از توالی های CoT در نمونه هایی از چند شات، از مدل های زبان خارج از قفسه به اندازه کافی بزرگ استخراج کرد.
-
صفر شات CoT. عبارات زبان طبیعی برای تشویق مدل به تولید زنجیره های استدلال استفاده می شود.
-
چند شات CoT. این مدل با چند نمایش یا مثال با کیفیت بالا برای ایجاد نتیجه تحریک می شود. این رویکرد در این مطالعه مورد استفاده قرار گرفت تا در نهایت به پاسخ نهایی منتهی شود زیرا مزایای آن برای کارهای استدلالی پیچیده با مدلهای زبانی بزرگتر آشکارتر است.
با درخواست CoT، آشکار است که یک پاسخ مستقیم مستقیم امکان پذیر بود اما به دلیل اطلاعات محدودی که درخواست درون متنی می تواند ارائه دهد، داده نشد. با این حال، ارزش تحریک CoT دلایل بیشتری را ارائه میکند که به کاربر LLM کمک میکند تا بهتر تصمیم بگیرد که چه پاسخی مناسبتر است، که، در این مورد، بسته به دورههای اوج مصرف، یا یک مرکز خرید یا یک ایستگاه قطار است. این نشان می دهد که چگونه ارائه CoT برای تحریک می تواند به طور قابل توجهی توانایی LLM را برای انجام استدلال پیچیده بهبود بخشد.
۲٫۴٫ دانش آفرینی و دانش سازی
۳٫ مواد و روشها
۳٫۱٫ طراحی CoT برای ایجاد دانش
-
سؤالات دانشآموزان، بهعنوان بخشی از دانشسازی، میتوانند به چند مرحله میانی تقسیم شوند تا بهعنوان اعلان اجرا شوند.
-
CoT میتواند به اندازه کافی زمینهای شود و با اطلاعات تکمیل شود تا پنجره کافی از تفسیر را فراهم کند و بنابراین، فضایی را برای ایدهها در خروجی تولید شده بهطور کامل بیان کند.
-
استدلال CoT می تواند برای استدلال عقل سلیم به عنوان بخشی از همسویی با نیازهای ایجاد دانش در محیط ساخت دانش استفاده شود.
-
استدلال CoT را می توان در LLM با گنجاندن نمونه هایی از دنباله های CoT در نمونه هایی از تحریک چند شات استخراج کرد.
در این مطالعه، ما مشاهده کردیم که چگونه می توان از استدلال CoT با استدلال عقل سلیم برای ایجاد دانش با قالب بندی مجدد سؤالات واقعی دانش آموزان از تنظیمات یادگیری معتبر با درخواست CoT و سپس وارد کردن آنها در یک LLM قبل از مقایسه خروجی ها با پاسخ های واقعی دانش آموزان برای تعیین استفاده کرد. سودمندی CoT باعث می شود. مقایسهها و خروجیهای بهدستآمده به مربیان و دانشآموزان درباره نحوه استفاده از CoT برای کمک به سفر خود در ساخت دانش و بهبود ایدههای دانشآموزان با LLM اطلاع میدهد.
۳٫۲٫ تنظیمات، شرکت کنندگان و راه اندازی
۳٫۲٫۱٫ زمینه و ماهیت سوالات دانش آموزان
این مطالعه از یک طرح نیمه تجربی پیروی کرد، با دادههای بهدستآمده از یک محیط آموزشی معتبر که بهعنوان یک استودیوی طراحی ساختمان دانش دانشجویی (sKBDS) طراحی و اجرا شد. موضوع روی پایداری متمرکز بود و این رویداد در نوامبر ۲۰۲۱ برگزار شد. قبل از جمعآوری و تجزیه و تحلیل دادهها، یک بررسی اخلاقی تأیید شد و مجوز از دانشگاه درخواست شد. در مجموع ۳۱ دانشآموز شرکتکننده از مدارس ابتدایی و متوسطه (بین کلاسهای ۵ و ۱۰) تحت دو روز تسهیل و کاوش آنلاین برای بررسی مشکلات دنیای واقعی مرتبط با موضوع قرار گرفتند و سؤالات آنها از یکدیگر در انجمن دانش پست شد. ماهیت سؤالات دانش آموز آمیزه ای از علوم طبیعی و علوم اجتماعی بود که از سؤالات ساده تا سؤالات همراه با توجیه و توضیح را در بر می گرفت زیرا دانش آموزان به دنبال پاسخ برای سؤالات خود بودند.
۳٫۲٫۲٫ استخراج جفت پرسش و پاسخ
جفتهای پرسش و پاسخی که دانشآموزان در تالار دانش پست میکردند، شامل پرسشها و پاسخهای دانشآموزان درباره یک موضوع میشد و عمدتاً برای شفافسازی یک موضوع مورد بحث، مرور یک فعالیت اخیراً تکمیلشده یا بهعنوان بخشی از آمادهسازی برای ارائه استفاده میشد. یک جفت پرسش و پاسخ کامل مستلزم یک پرسش است که با موضوع sKBDS در مورد پایداری (به عنوان مثال، “کربن چگونه به وجود آمد؟”) و نه صرفاً صحبت های معمولی (مثلا، چه نوشیدنی هایی؟ چای حباب دار؟)، و به دنبال آن یک پاسخ مناسب از یک شرکتکننده دیگر در sKBDS زمانبندی پاسخ ناهمزمان و محدود به پاسخهای به دست آمده از دو روز تسهیل بود.
بهعنوان بخشی از فرآیند پاکسازی دادهها و برای تحقق اهداف این مطالعه، تنها جفتهای پرسش-پاسخ کامل برای استفاده در نظر گرفته شدند، زیرا نیاز به مقایسه خروجیهای LLM با پاسخهای انسانی اصلی بود که به ما اجازه میداد در مورد سودمندی بحث کنیم. CoT. از ۷۲۱ نوبت گفتمانی که در طول رویداد دو روزه sKBDS جمعآوری شد، ۲۷۲ جفت پرسش-پاسخ کامل به عنوان دادههای مرتبط و قابل استفاده شناسایی شدند و ۱۴۹ موضوع بحث را تشکیل دادند. در این مقاله، ما دو رشته از جفتهای پرسش و پاسخ کامل را در یافتهها نشان میدهیم تا کاربرد بالقوه CoT برای حمایت از ایدههای قابل بهبود در زمینه ایجاد دانش و دانشسازی را به نمایش بگذاریم.
۳٫۲٫۳٫ استخراج جفت پرسش و پاسخ
۳٫۲٫۴٫ انتخاب مدل زبان بزرگ (LLM)
GPT-3.5 Turbo به عنوان LLM برای استفاده در این مطالعه انتخاب شد. اگرچه شبیه به سایر LLM ها مانند BERT و PalM است، عملکرد خوب GPT در اکثر وظایف و موضوعات آن را به انتخاب ترجیحی تبدیل کرده است. علاوه بر این، سهولت دسترسی به GPT3.5 Turbo از طریق رابط برنامه نویسی کاربردی (API) دلیل دیگری برای انتخاب آن برای پیاده سازی است. آزمایش اولیه با مدلهای نوظهور (به عنوان مثال، GPT4، GPT4o) پاسخهایی با سطح کیفی مشابه با انتظارات نشان داد و انتظار میرود روش پیشنهادی در این مطالعه برای ایجاد دانش، حتی با وجود نسخههای LLM که در آینده نزدیک عرضه شوند، عملکرد خوبی داشته باشد.
۴٫ نتایج
در مجموع ۷۲۱ نوبت گفتمان مورد بررسی قرار گرفت و ۲۷۲ جفت پرسش-پاسخ حاوی محتوای مرتبط با بحث در مورد پایداری یافت شد. این نشان میدهد که ۷۹ درصد پستهای دانشآموز مرتبط بوده و سایر چرخشهای گفتمان یا صحبتهای پیش پا افتاده یا معمولی بوده و بنابراین تحلیل نشدهاند. در بین زوجهای پرسش و پاسخ مربوطه، ۱۴۹ موضوع بحث دانشجویی با حداقل عمق موضوع ۳ یافت شد و طولانیترین موضوع در عمق ۹ دارای سه شرکتکننده مختلف بود.
۴٫۱٫ اولین تصویر از داده های تجربی
یکی از مزیتهای خوردن گوشتهای گیاهی، پتانسیل آن برای داشتن اثرات زیستمحیطی کمتر در مقایسه با گوشتهای سنتی حیوانی است. گوشتهای گیاهی اغلب با استفاده از منابع کمتر و تولید گازهای گلخانهای کمتری نسبت به پرورش و فرآوری حیوانات برای گوشت تولید میشوند. این می تواند به کاهش ردپای کربن کلی مرتبط با تولید مواد غذایی کمک کند، علاوه بر این، گوشت های گیاهی می توانند طعم و بافتی مشابه با گوشت های سنتی داشته باشند، و آنها را به گزینه ای مناسب برای افرادی تبدیل می کند که می خواهند مصرف گوشت خود را برای سلامتی و اخلاقی کاهش دهند. یا دلایل زیست محیطی بدون دست کشیدن کامل از طعم ها و غذاهایی که از آنها لذت می برند.
۴٫۲٫ تصویر دوم از داده های تجربی
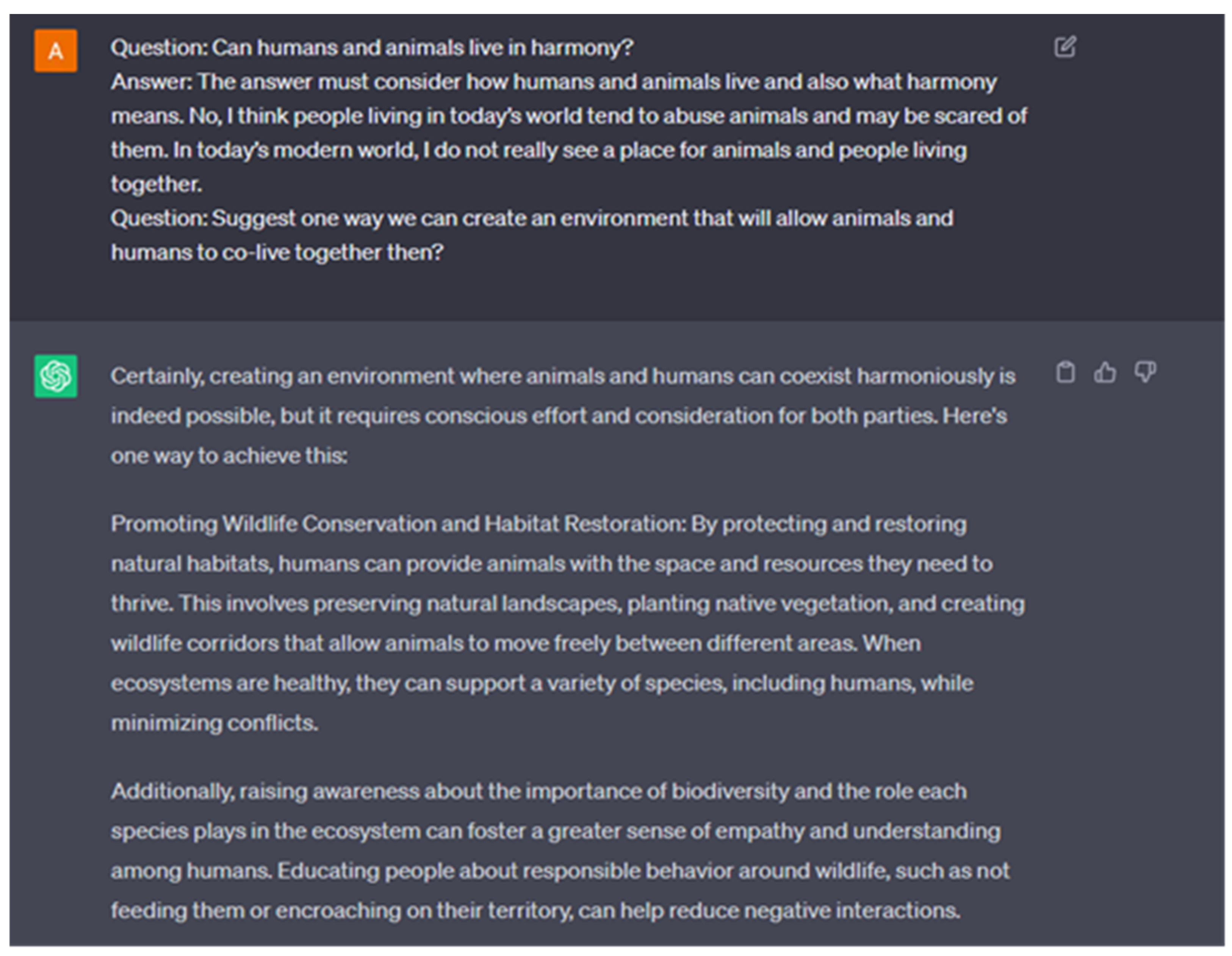
“مسلماً، ایجاد محیطی که در آن حیوانات و انسان ها بتوانند به طور هماهنگ همزیستی کنند، واقعاً امکان پذیر است، اما این امر مستلزم تلاش و توجه آگاهانه از سوی طرفین است. در اینجا یک راه برای دستیابی به این هدف وجود دارد: ترویج حفاظت از حیات وحش و احیای زیستگاه: با حفاظت و احیای زیستگاه های طبیعی، انسان ها می تواند فضا و منابع مورد نیاز حیوانات را برای رشد و نمو فراهم کند. از جمله انسانها، ضمن به حداقل رساندن تعارضها، افزایش آگاهی در مورد اهمیت تنوع زیستی و نقشی که هر گونه در اکوسیستم ایفا میکند، میتواند حس همدلی و درک بیشتری را در بین انسانها ایجاد کند، مانند عدم تغذیه آنها یا تجاوز به قلمرو آنها، می تواند به کاهش تعاملات منفی کمک کند».
۵٫ بحث و محدودیت
تحریک CoT به عنوان یک جایگزین مناسب برای برانگیختن رفتار استدلال چند مرحله ای در LLM برای اهداف ایجاد دانش مورد بررسی قرار گرفته است. برای حوزه خاص استدلال عقل سلیم که با حوزههای ایجاد دانش و دانشسازی همسو است، یافتهها نشان میدهند که تمرکز فقط بر دستیابی به اهداف عقل سلیم نیست، بلکه به دست آوردن بهبود کیفیت محتوا و ایدههای تولید شده توسط LLM است. افزایش تنوع ایده ها که به دانش آموزان اجازه می دهد کار خود را بهبود بخشند. این از یافتههای ما مشهود است، و بحث زیر تفاوتهای بین این دو تصویر را توضیح خواهد داد.
در تصویر اول، از یک سو، پاسخی که توسط دانش آموز ایجاد شده توسط انسان به عنوان پاسخی مستقیم می بینیم که ساده است و بحث بعدی را آغاز می کند. با این حال، کمبود محتوا و محتوایی در برانگیختن افکار عمیقتر است که ممکن است به دیگران در بهبود ایدههایشان کمک کند. از سوی دیگر، پاسخ تولید شده توسط LLM نه تنها پاسخی دقیق و دقیقتر است، بلکه از نمونههای CoT برای هدایت پاسخ و ارائه دلایلی در مورد اینکه چرا گوشتهای گیاهی انتشار گازهای گلخانهای کمتری تولید میکنند نیز استفاده میکند. LLM همچنین پیامدهای اضافی و توضیحات بیشتری ایجاد کرد، اگرچه اینها ضمانت نداشتند، اما احتمالاً این ویژگی نیز بود که LLM تصمیم گرفت در خروجی خود قرار دهد.
در تصویر دوم، زمانی که نمونههای اضافی با درخواست CoT در پاسخ اصلی A1 گنجانده شد، خروجی تولید شده توسط LLM تفاوت قابلتوجهی را نشان میدهد که نمونههای CoT میتوانند در تشویق LLM برای تولید خروجی بسیار متنوعتر و با کیفیتتر ایجاد کنند. علاوه بر ارائه توضیحات بیشتر برای پرداختن به این سوال، خروجی حاصل از ماهیت پیشبینیکنندهتر و حتی تجویزیتر شد، با پیشنهاداتی که به نحوه آموزش مردم درباره رفتار مسئولانه در اطراف حیات وحش میتواند به کاهش تعاملات منفی کمک کند.
بعلاوه، اگرچه نمونههایی از دادههای گفتمان واقعی دانشآموز ارائه کردهایم، بعید است که اکثر دانشآموزان بتوانند در هنگام اجرای چند شات از نمونههای CoT پرس و جو کنند، اما این امکان وجود دارد که به دانشآموزان بر این اساس در مورد نحوه استفاده از آن آموزش داده شود. LLM به شیوه ای مناسب و برای هدف مورد نظر. با این حال، این به این معنی است که استفاده از CoT برای افزایش پرسشهای دانشآموزان ممکن است بسیار دشوار باشد و باید در این مرحله به صورت دستی انجام شود، در حالی که مقیاسبندی درخواستهای CoT ممکن است نیاز به بلوغ فناوری یا تجدید نظر در مورد تعداد کمی داشته باشد. فرآیندهای شات در نهایت می تواند به تعمیم صفر شات تبدیل شود که می تواند به عنوان بخشی از یادگیری تقویتی عمیق انجام شود. آخرین، اما نه کماهمیت، CoT به دلیل LLMها میتواند مورد استفاده قرار گیرد و این امکان وجود دارد که استفاده از آن در حال حاضر در سایر برنامههای همزمان که از مدلهای کوچکتر استفاده میکنند به دلیل محدودیت هزینه و سایر منابع مادی، بازدارنده باشد.
۶٫ نتیجه گیری
این مطالعه چشماندازی در مورد اینکه چگونه دانشآموزان و حتی مربیان میتوانند از LLM برای حمایت از فرآیندهای ایجاد دانش و دانشسازی از طریق استفاده از نمونههای چندتایی افزوده شده به CoT بهره ببرند، ارائه کرده است. اگرچه درخواستها بهصورت دستی پیرامون پرسشهای معتبر دانشآموزان ساخته شدهاند، نتایج نشان میدهد که در این محیطهای آموزشی معتبر نیز است که تحریک CoT پاسخهای بهبود یافتهای را ایجاد میکند که روشنتر از پاسخهای دانشآموزان است، که از نظر محتوا و دامنه محدود هستند.
به طور کلی، ممکن است، اما غیرمعمول است که برخی از دانشآموزان بتوانند سؤالاتی را انجام دهند که قبلاً شبیه به چند ضربه CoT است تا به یادگیری کمک کند. بنابراین، ما از طریق این مطالعه پیشنهاد می کنیم که رویکرد کلی استفاده از CoT برای پرس و جو می تواند بخشی از سواد لازم و داربست مورد نیاز برای نوشتن و ایجاد سوالاتی باشد که برای اهداف ایجاد دانش و دانش سازی حیاتی هستند.
مشارکت های نویسنده
مفهوم سازی، AVYL، CLT و SCT. مدیریت داده، AVYL و CLT. تجزیه و تحلیل رسمی، AVYL; بررسی، AVYL و CLT. روش شناسی، AVYL; منابع، AVYL و CLT. نرم افزار AVYL; اعتبارسنجی، AVYL، CLT و SCT. تجسم، AVYL; نوشتن – پیش نویس اصلی، AVYL; نوشتن-بررسی و ویرایش، AVYL، CLT و SCT همه نویسندگان نسخه منتشر شده نسخه خطی را خوانده و با آن موافقت کرده اند.
تامین مالی
این تحقیق هیچ بودجه خارجی دریافت نکرد.
بیانیه هیئت بررسی نهادی
این مطالعه مطابق با قانون حفاظت از دادههای شخصی انجام شد و توسط هیئت بررسی نهادی دانشگاه فناوری نانیانگ (IRB-2019-10-034، تأیید شده اکتبر ۲۰۱۹) تأیید شد.
بیانیه رضایت آگاهانه
رضایت آگاهانه از همه افراد درگیر در مطالعه اخذ شد.
بیانیه در دسترس بودن داده ها
مجموعه داده های ارائه شده در این مقاله به دلیل قوانین مالکیت معنوی، حریم خصوصی و اخلاقی که توسط IRB دانشگاه تعیین شده است، به راحتی در دسترس نیستند. درخواست های دسترسی به مجموعه داده ها باید به نویسنده مربوطه ارسال شود.
قدردانی ها
نظرات بیان شده در این مقاله متعلق به نویسندگان است و لزوماً بیانگر دیدگاه های موسسه میزبان نیست. تیم تحقیق از مربیان و دانشجویان شرکت کننده در این مطالعه تشکر می کند.
تضاد منافع
نویسندگان هیچ تضاد منافعی را اعلام نمی کنند.
ضمیمه A
موارد زیر تصاویری از دستورات گزارش شده و مورد استفاده در این مقاله است که بر اساس ترتیب زمانی ذکر در چندین شکل ادغام شده است.
پاسخهای LLM بر اساس شات صفر (بالا)، یک تیر (وسط) و چند تیر (پایین) برانگیختن
شکل A1.
پاسخهای LLM بر اساس شات صفر (بالا)، یک تیر (وسط) و چند تیر (پایین) برانگیختن
خروجی LLM از وظیفه استدلال عامیانه.
شکل A2.
خروجی LLM از وظیفه استدلال عامیانه.
مقایسه خروجی LLM با استفاده از دستور استاندارد (بالا(در مقابل درخواست CoT)پایین).
شکل A3.
مقایسه خروجی LLM با استفاده از دستور استاندارد (بالا(در مقابل درخواست CoT)پایین).

خروجی تولید شده توسط LLM تصویر ۱ پس از درخواست CoT در پاسخ اول افزوده شد.
شکل A4.
خروجی تولید شده توسط LLM تصویر ۱ پس از درخواست CoT در پاسخ اول افزوده شد.

خروجی دقیقتر تصویر ۲ که توسط LLM تولید میشود، پس از استفاده از نمونههای CoT اضافی در درخواست استفاده شد.
شکل A5.
خروجی دقیقتر تصویر ۲ که توسط LLM تولید میشود، پس از استفاده از نمونههای CoT اضافی در درخواست استفاده شد.
مراجع
- هادی، MU; قریشی، ر. شاه، ع. عرفان، م. ظفر، ع. شیخ، MB; اختر، ن. وو، جی. میرجلیلی، س. بررسی مدلهای زبان بزرگ: کاربردها، چالشها، محدودیتها و کاربرد عملی. TechRxiv2023; پیش چاپ. [Google Scholar] [CrossRef]
- پااوولا، اس. لاسه، ال. کای، اچ. مدلهای جوامع دانش نوآورانه و سه استعاره از یادگیری. کشیش. Res. 2004، ۷۴۵۵۷–۵۷۶٫ [Google Scholar] [CrossRef]
- بریتر، سی. مارلین، اس. یادگیری کار خلاقانه با دانش. در محیطهای یادگیری قدرتمند: بازگشایی اجزا و ابعاد اساسی; De Erik, C., Lieven, V., Noel, E., Jeroen Van, M., Eds. چاپ پرگامون: آکسفورد، انگلستان، ۲۰۰۳; pp. 55-68. [Google Scholar]
- Scardamalia، M. CSILE/ انجمن دانش®. در آموزش و فناوری: یک دایره المعارف; ABC-CLIO: سانتا باربارا، کالیفرنیا، ایالات متحده آمریکا، ۲۰۰۴; ص ۱۸۳-۱۹۲٫ [Google Scholar]
- هاکاراینن، ک. پااوولا، اس. کانگاس، ک. Seitamaa-Hakkarainen، P. دیدگاه های اجتماعی در مورد یادگیری مشارکتی: به سوی ایجاد دانش مشارکتی. در کتابچه راهنمای بین المللی یادگیری مشارکتی; Cindy, H.-S., Clark, C., Carol, C., O'Donnell, A., Eds.; Routledge: نیویورک، نیویورک، ایالات متحده آمریکا، ۲۰۱۳; صص ۵۷-۷۳٫ [Google Scholar]
- لی، AVY؛ Tan, SC ایده های امیدوارکننده برای پیشرفت جمعی دانش جمعی با استفاده از تجزیه و تحلیل زمانی و تجزیه و تحلیل خوشه ای. J. یاد بگیرید. مقعدی ۲۰۱۷، ۴۷۶-۱۰۱٫ [Google Scholar] [CrossRef]
- لیو، وی. لیدیا، BC دستورالعمل های طراحی برای مهندسی سریع مدل های تولیدی متن به تصویر. در مجموعه مقالات کنفرانس CHI 2022 در مورد عوامل انسانی در سیستم های محاسباتی، نیواورلئان، لس آنجلس، ایالات متحده آمریکا، ۲۹ آوریل ۲۰۲۲؛ صص ۱-۲۳٫ [Google Scholar]
- Rae, JW; بورگو، اس. کای، تی. میلیکن، ک. هافمن، جی. آهنگ، اف. اصلانیدس، ج. هندرسون، اس. حلقه، آر. جوان، اس. و همکاران مقیاسبندی مدلهای زبان: روشها، تجزیه و تحلیل و بینش از آموزش گوفر. arXiv 2021arXiv:2112.11446. [Google Scholar] [CrossRef]
- کاب، ک. کوساراجو، وی. باواریا، م. چن، ام. جون، اچ. قیصر، ال. پلپرت، ام. توورک، جی. هیلتون، جی. ناکانو، آر. و همکاران آموزش تایید کننده ها برای حل مسائل ریاضی. arXiv 2021arXiv:2110.14168. [Google Scholar] [CrossRef]
- براون، تی. مان، بی. رایدر، ن. سببیه، م. کاپلان، جی دی. ذریوال، ص. Neelakantan، A. شیام، پ. ساستری، جی. آسکل، آ. و همکاران مدلهای زبان، یادگیرندههای کمی هستند. Adv. عصبی Inf. فرآیند. سیستم ۲۰۲۰، ۳۳۱۸۷۷-۱۹۰۱٫ [Google Scholar]
- وایت، جی. فو، س. هایس، اس. سندبورن، م. اولیا، سی. گیلبرت، اچ. النشر، ع. اسپنسر اسمیت، جی. Schmidt, DC کاتالوگ الگوی سریع برای بهبود مهندسی سریع با chatgpt. arXiv 2023arXiv:2302.11382. [Google Scholar] [CrossRef]
- لیو، پی. یوان، دبلیو. فو، جی. جیانگ، ز. هایاشی، ح. Neubig, G. Pre-train, prompt, and predict: یک بررسی سیستماتیک از روش های تحریک در پردازش زبان طبیعی. کامپیوتر ACM. Surv. 2023، ۵۵۱-۳۵٫ [Google Scholar] [CrossRef]
- وی، جی. وانگ، ایکس. شوورمنز، دی. بوسما، م. شیا، اف. چی، ای. Le، QV; ژو، دی. برانگیختن زنجیرهای از فکر، استدلال را در مدلهای زبانی بزرگ برمیانگیزد. Adv. عصبی Inf. فرآیند. سیستم ۲۰۲۲، ۳۵۲۴۸۲۴–۲۴۸۳۷٫ [Google Scholar]
- دوست خوب، من. پوگت آبادی، ج. میرزا، م. خو، بی. وارد-فارلی، دی. اوزایر، س. کورویل، آ. Bengio، Y. شبکه های متخاصم مولد. اشتراک. ACM 2020، ۶۳۱۳۹-۱۴۴٫ [Google Scholar] [CrossRef]
- Westerlund، M. ظهور فناوری دیپ فیک: یک بررسی. تکنولوژی نوآوری. مدیریت کشیش ۲۰۱۹، ۹۳۹-۵۲٫ [Google Scholar] [CrossRef]
- اوپارا، ای. Mfon-Ette ترزا، A. Aduke، TC ChatGPT برای آموزش، یادگیری و تحقیق: چشماندازها و چالشها. گلوب. آکادمی J. Humanit. Soc. علمی ۲۰۲۳، ۵۳۳-۴۰٫ [Google Scholar]
- لی، ا. Vwen، Y. پیشروی با هوش مصنوعی مولد برای یادگیری: پیمایش چالشها و فرصتها با ۵Ts و ۳Rs. آسیا پک J. Educ. 2024، ۴۴۸۱-۹۳٫ [Google Scholar] [CrossRef]
- لی، AVY؛ قهوهای مایل به زرد، SC; Teo، CL با استفاده از هوش مصنوعی مولد برای گفتمان دانشجویی و ایجاد دانش پایدار طراحی و تمرین می کند. یادگیری هوشمند. محیط زیست. ۲۰۲۳، ۱۰۵۹٫ [Google Scholar] [CrossRef]
- Halaweh, M. ChatGPT در آموزش: راهبردهایی برای اجرای مسئولانه. تحقیر کردن آموزش دهید تکنولوژی ۲۰۲۳، ۱۵ep421. [Google Scholar] [CrossRef] [PubMed]
- لستر، بی. الرفو، ر. ثابت، N. قدرت مقیاس برای تنظیم سریع پارامتر کارآمد. arXiv 2021arXiv:2104.08691. [Google Scholar] [CrossRef]
- ژانگ، ز. ژانگ، ا. لی، ام. اسمولا، الف. ایجاد زنجیره خودکار افکار در مدل های زبان بزرگ. arXiv 2022arXiv:2210.03493. [Google Scholar] [CrossRef]
- شوم، ک. دیائو، اس. Zhang, T. افزایش خودکار و انتخاب سریع با زنجیره ای از افکار از داده های برچسب دار. arXiv 2023arXiv:2302.12822. [Google Scholar] [CrossRef]
- تالمور، ا. هرزیگ، جی. لوری، ن. Berant, J. CommonsenseQA: پرسشی در پاسخ به چالشی که دانش عام را هدف قرار می دهد. arXiv 2018arXiv:1811.00937. [Google Scholar] [CrossRef]
- وانگ، ایکس. وی، جی. شوورمنز، دی. لی، کیو. چی، ای. نارنگ، س. خودسازگاری زنجیره استدلال فکری را در مدل های زبانی بهبود می بخشد. arXiv 2022arXiv:2203.11171. [Google Scholar] [CrossRef]
- ایوانز، جی. شهود و استدلال: دیدگاه دو فرآیندی. روانی شرکت ۲۰۱۰، ۲۱۳۱۳-۳۲۶٫ [Google Scholar] [CrossRef]
- قهوهای مایل به زرد، SC; چان، سی. Bielaczyc، K. ما، ال. اسکاردامالیا، م. بریتر، سی. ساخت دانش: همسویی آموزش با نیازهای ایجاد دانش در عصر دیجیتال. آموزش. تکنولوژی Res. توسعه دهنده ۲۰۲۱، ۶۹۲۲۴۳-۲۲۶۶٫ [Google Scholar] [CrossRef]
- اسکاردامالیا، ام. مسئولیت شناختی جمعی برای پیشرفت دانش. در آموزش لیبرال در یک جامعه دانش; دادگاه آزاد: شیکاگو، IL، ایالات متحده آمریکا، ۲۰۰۲; صص ۶۷-۹۸٫ [Google Scholar]
- لیو، ایکس. وو، زی. وو، ایکس. لو، پی. چانگ، KW; فنگ، ی. آیا lms قادر به استدلال آماری و علی مبتنی بر داده است؟ محک زدن استدلال کمی پیشرفته با داده ها arXiv 2024arXiv:2402.17644. [Google Scholar] [CrossRef]
مقایسه پاسخهای A2 و A2*، که به ترتیب توسط انسانها (مسیر سمت چپ) ارائه شده و توسط LLM با استفاده از نمونههای تقویتشده با درخواست چند شات CoT (مسیر راست) تولید شدهاند.
شکل ۱٫
مقایسه پاسخهای A2 و A2*، که به ترتیب توسط انسانها (مسیر سمت چپ) ارائه شده و توسط LLM با استفاده از نمونههای تقویتشده با درخواست چند شات CoT (مسیر راست) تولید شدهاند.

تصویر ۱ که پاسخهای انسانی (A2) را با پاسخ LLM (A2*) مقایسه میکند که از پاسخ CoT افزوده شده (Italicized) (A1*) به عنوان ورودی ایجاد میشود.
شکل ۲٫
تصویر ۱ که پاسخهای انسانی (A2) را با پاسخ LLM (A2*) مقایسه میکند که از پاسخ CoT افزوده شده (Italicized) (A1*) به عنوان ورودی ایجاد میشود.

تصویر ۲٫ نشانههای CoT در پاسخ اصلی (A1) اما هنوز تفاوتهایی بین پاسخ انسانی (A2) و پاسخ LLM (A2*) مشاهده میشود به دلیل استفاده از پاسخ CoT افزوده (مورب) (A1*) به عنوان ورودی
شکل ۳٫
تصویر ۲٫ نشانههای CoT در پاسخ اصلی (A1) اما هنوز تفاوتهایی بین پاسخ انسانی (A2) و پاسخ LLM (A2*) مشاهده میشود به دلیل استفاده از پاسخ CoT افزوده (مورب) (A1*) به عنوان ورودی
نمونه هایی از درخواست صفر، تک شات و چند شات در قالب پرسش و پاسخ بر اساس موضوعاتی که دانش آموزان می پرسند (تصاویر ورودی ها و خروجی ها را می توان در شکل A1 پیوست A مشاهده کرد).
نمونه هایی از درخواست صفر، تک شات و چند شات در قالب پرسش و پاسخ بر اساس موضوعاتی که دانش آموزان می پرسند (تصاویر ورودی ها و خروجی ها را می توان در شکل A1 پیوست A مشاهده کرد).
| رویکردها | قالب | ورودی | خروجی |
|---|---|---|---|
| ضربه صفر | پاسخ درست یا غلط: سوال: آیا بازیافت به تنهایی گرمایش جهانی را معکوس می کند؟ |
نادرست | |
| تک شات | به کدام دستگاه پاسخ دهید: سوال: کدام وسیله در یک بازه زمانی مشابه برق بیشتری مصرف می کند، لپ تاپ یا رومیزی؟ پاسخ: رومیزی سوال: کدام وسیله در همان مدت زمان برق بیشتری مصرف می کند، آبگرمکن یا یخچال؟ |
آبگرمکن | |
| چند شات | پاسخ ایده خوب یا بد: سوال: آیا میتوانیم لوازم خانگی را در حالت آمادهبهکار نگه داریم، وقتی از آنها استفاده نمیکنیم؟ پاسخ : فکر بد. سوال: شاید در صورت تبدیل شدن به زباله های پلاستیکی در اقیانوس، کمتر از پلاستیک استفاده کنیم؟ پاسخ: ایده خوبی است. سوال: آیا همه منابع انرژی تجدیدپذیر باید خورشیدی باشند؟ پاسخ : فکر بد. سوال: آیا بهتر است برای کاهش انتشار گازهای گلخانه ای به خوردن سبزیجات بیشتر تشویق شود؟ |
ایده خوبیه |
مثالی از استدلال عقل سلیم با استفاده از LLM (تصویر صفحه ورودی و خروجی را می توان در شکل A2 پیوست A یافت).
مثالی از استدلال عقل سلیم با استفاده از LLM (تصویر صفحه ورودی و خروجی را می توان در شکل A2 پیوست A یافت).
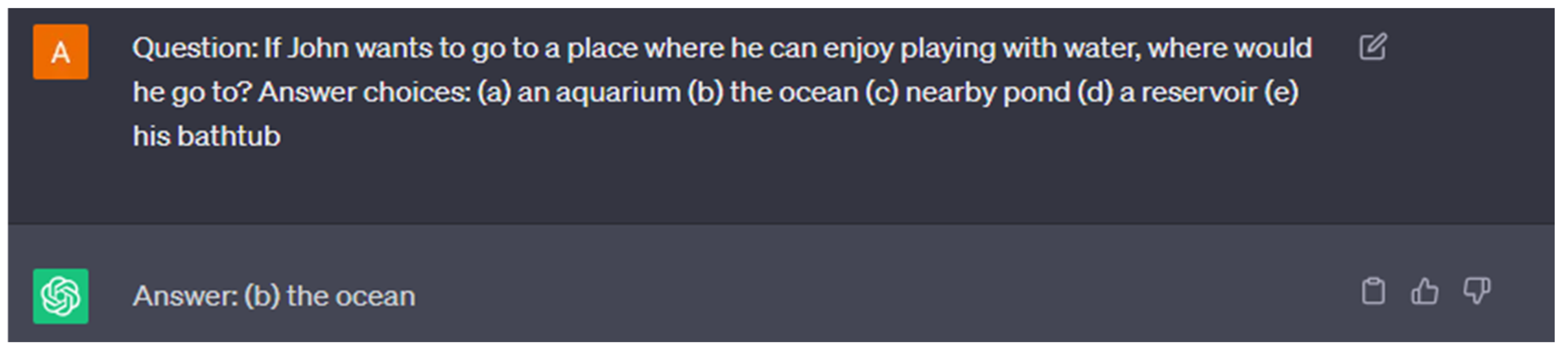
| سوال: اگر جان بخواهد به جایی برود که از آب بازی لذت ببرد، کجا می رود؟ گزینه های پاسخ: (الف) آکواریوم (ب) اقیانوس (ج) حوضچه نزدیک (د) یک مخزن (ه) وان حمام او
جواب: ب) اقیانوس |
مقایسه اعلان استاندارد با درخواست زنجیره ای فکر (CoT) (تصاویر ورودی ها و خروجی ها را می توان در شکل A3 پیوست A یافت).
مقایسه اعلان استاندارد با درخواست زنجیره ای فکر (CoT) (تصاویر ورودی ها و خروجی ها را می توان در شکل A3 پیوست A یافت).
| رویکردها | قالب | ورودی | خروجی |
|---|---|---|---|
| درخواست استاندارد | سوال: جان می خواهد از مکان هایی که کمتر شلوغ هستند لذت ببرد. او به کجا می تواند برود؟ گزینه های پاسخ: (الف) یک مرکز خرید (ب) یک پارک (ج) یک ایستگاه قطار (د) یک راهرو (ه) در کنار جاده جواب: (ب) پارک سوال: جان دوست دارد از مناطق شلوغ بازدید کند. او به کجا می تواند برود؟ گزینه های پاسخ: (الف) یک مرکز خرید (ب) یک پارک (ج) یک ایستگاه قطار (د) یک راهرو (ه) در کنار جاده |
جواب: الف) مرکز خرید | |
| درخواست CoT (مورب) | سوال: جان می خواهد از مکان هایی که کمتر شلوغ هستند لذت ببرد. او به کجا می تواند برود؟ گزینه های پاسخ: (الف) یک مرکز خرید (ب) یک پارک (ج) یک ایستگاه قطار (د) یک راهرو (ه) در کنار جاده پاسخ: پاسخ باید جایی باشد که افراد کمتری داشته باشد. از بین گزینه های داده شده، یک پارک جمعیت کمتری دارد و از یک راهرو یا کنار جاده لذت بخش تر است. بنابراین پاسخ (ب) پارک است سوال: جان دوست دارد از مناطق شلوغ بازدید کند. او به کجا می تواند برود؟ گزینه های پاسخ: (الف) یک مرکز خرید (ب) یک پارک (ج) یک ایستگاه قطار (د) یک راهرو (ه) در کنار جاده |
پاسخ: پاسخ باید مکانی با افراد بیشتر باشد. از میان گزینههای ارائه شده، یک مرکز خرید، یک ایستگاه قطار، و احتمالاً یک پارک در زمانهای اوج مصرف در مقایسه با یک راهرو یا کنار جاده، جمعیت بیشتری خواهد داشت. بنابراین، پاسخ می تواند (الف) یک مرکز خرید یا (ج) یک ایستگاه قطار باشد. |
جدول ۴٫
چند نمونه تصویری که نشان میدهد چگونه میتوانیم برانگیختگی زنجیرهای از فکر (مورب) را به سؤالات و پاسخهای موجود برای ایجاد دانش اضافه کنیم.
جدول ۴٫
چند نمونه تصویری که نشان میدهد چگونه میتوانیم برانگیختگی زنجیرهای از فکر (مورب) را به سؤالات و پاسخهای موجود برای ایجاد دانش اضافه کنیم.
| سوال ۱: اگر بخواهیم انتشار کربن را کاهش دهیم، چه کاری باید انجام دهیم؟ گزینه های پاسخ: (الف) استفاده از گاز طبیعی (ب) استفاده از سوخت های فسیلی (ج) با استفاده از انرژی باد (د) با استفاده از انرژی خورشیدی
پاسخ ۱: پاسخ باید قادر به کاهش انتشار کربن باشد. از میان گزینه های فوق، سوخت های فسیلی بیشترین انتشار کربن را دارند. بنابراین، پاسخ (ب) استفاده از سوختهای فسیلی است. – پرسش و پاسخ جداگانه – سوال ۲: کدام راه از سفر به مدرسه سازگارتر با محیط زیست و پایدار است؟ گزینه های پاسخ: (الف) با ماشین برقی شخصی (ب) با اتوبوس عمومی دیزلی (ج) با تاکسی برقی عمومی (د) با قطار برقی عمومی پاسخ ۲: در پاسخ باید توجه داشت که حمل و نقل عمومی مقرون به صرفه تر از حمل و نقل خصوصی است و سپس اندازه صندلی حمل و نقل. از میان گزینه های فوق، حمل و نقل عمومی که وسیله نقلیه الکتریکی است سازگارتر با محیط زیست و پایدارتر است. بنابراین، پاسخ (د) توسط قطارهای برقی عمومی است. |
|
سلب مسئولیت/یادداشت ناشر: اظهارات، نظرات و داده های موجود در همه نشریات صرفاً متعلق به نویسنده (ها) و مشارکت کننده (ها) است و نه MDPI و/یا ویرایشگر(ها). MDPI و/یا ویراستار(های) مسئولیت هرگونه آسیب به افراد یا دارایی ناشی از هر ایده، روش، دستورالعمل یا محصولات اشاره شده در محتوا را رد می کنند. |
منبع: https://www.mdpi.com/2673-2688/5/3/69